
Embrace the timeless wisdom of prioritizing data quality as the linchpin of your machine learning strategy with insights from Data Quality: The Key to Unlocking the Value of Your Enterprise Information Asset, recognizing its instrumental role in achieving sustainable growth and competitive advantage.
Unleashing the Power of Data Integrity in Machine Learning and AI
Algorithms have superseded human intervention in data interpretation, heralding an era where computational insights reign supreme.
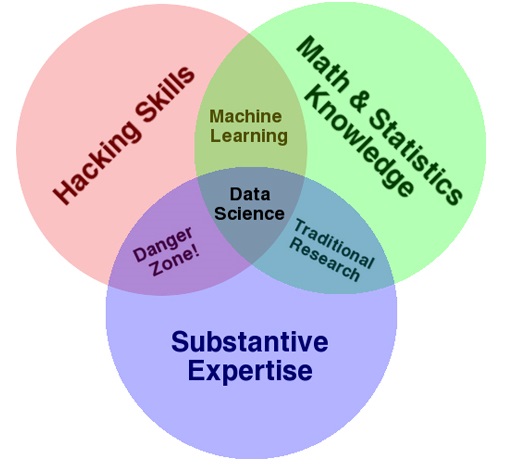
Machine learning and artificial intelligence are the new hot topics in data analytics.
These topics define subsets of data science that are primarily characterized by mathematical and statistical processes applied to data. In machine learning, algorithms replace humans in interpreting data.
The underlying premise is simple yet transformative – machines possess the capacity to make decisions propelled solely by data-driven considerations, potentially surpassing the decision-making abilities of their human counterparts.
However, the bedrock of this paradigm shift rests on a critical foundation – the quality of training data.
Machine learning requires quality training data
We assume that machines are not subject to emotion and that machine learning, therefore, is unbiased.
While machines may appear immune to emotional influences, the intrinsic bias embedded within the data exposes the inherent bias of machine learning itself. This revelation is underscored by an insightful analysis of the forthcoming Texas senate race, articulated by Nate Silver on fivethirtyeight.com:
“In crafting a statistical model, the ideal scenario involves occasional data-driven surprises—though not in excess. An absence of such surprises often signifies a lack of in-depth data examination, instead reflecting an imposition of assumptions onto the analysis, akin to an elaborate form of confirmation bias. Conversely, an incessant stream of surprises typically signifies deficiencies in the model or a lack of profound field comprehension. More often than not, these ‘surprises’ are, in essence, errors.”
Nate Silver
Evidently, the dual facets of both the model and the data demand rigorous testing and validation to underpin sound decision-making. The quintessential risk for machine learning lies in the potential shortfall of fundamental data management skills among the mathematical experts shaping these models.
In this evolving landscape, the pivotal role of data quality is incontrovertible. The quest for computational prowess through machine learning is intricately intertwined with the overarching mission of elevating data integrity, ensuring a symbiotic relationship between accurate data and transformative insights.

Amidst the interplay of mathematical acumen and data finesse, the realm of machine learning converges with the delicate art of data governance. It is within this convergence that the true potential of machine learning unfolds, illuminating the path towards more informed, astute, and impactful decision-making.
Embark on this transformative journey, where the nexus of machine learning and data quality fashions a future defined by intelligent algorithms and impeccable data integrity. A future where the subtlest nuances of data resonate to shape a world of uncharted possibilities.
Navigate the changing banking environment and position your organization for success with insights from How to succeed in a changing and disrupted banking environment, highlighting the indispensable role of data quality in driving innovation and resilience.
Gain foresight into the future of business and the factors that will shape its evolution with insights from What will be important in tomorrow’s business?, informing strategic planning and adaptation to emerging trends and technologies.

Leave a comment