
ETL defined
Extract, Transform and Load or ETL is a standard information management term used to describe a process for the movement and transformation of data.
ETL is commonly used to populate data warehouses and data marts, and for data migration, data integration and business intelligence initiatives.
Manual ETL vs Tools
ETL processes can be built by manually writing custom scripts or code, with the trade-off that as the complexity of the ETL operations increase, scripts become harder to maintain and update.
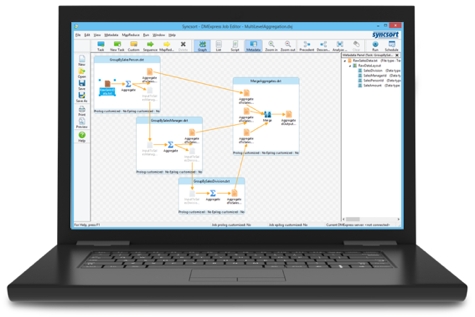
Alternatively, purpose-built ETL software may offer a graphical user interface to build and run ETL processes, which typically reduces development costs and improves maintainability.
The Three Stages of ETL

Extract
Extract data from one or more source systems containing customer, financial, or product data.
Modern organizations have data stored in many disparate systems such as customer relationship management (CRM), sales, accounting, and stock tracking to name just a few.
Each system will typically store data in different mutually incompatible formats. To obtain business value from all this data means the ETL software you choose should have the ability to extract data from many different sources.
Connectors: Flat files, XML, Oracle, IBM DB2, SQL Server, Teradata, Sybase, Vertica, Netezza, Greenplum, IBM Websphere MQ, ODBC, JDBC, Hadoop Distributed File System (HDFS), Hive/HCatalog, JSON, Kafka, Mainframe (IBM z/OS), Salesforce.com, SAP/R3
Transform
Transform the data by applying business rules, cleansing, and validating the data.
To combine and report on the data extracted in Stage 1, for example comparing orders from the order entry system with stock levels in the warehouse management system, may require multiple steps and many different operations. To meet the current and future requirements of the business, your ETL software should be able to perform all of the following types of operations:
- Transforms: Aggregation, Copy, Join, Sort, Merge, Partition, Filter, Reformat, Lookup
- Mathematical: +, -, x, /, Abs, IsValidNumber, Mod, Pow, Rand, Round, Sqrt, ToNumber, Truncate, Average, Min, Max
- Logical: And, Or, Not, IfThenElse, RegEx, Variables
- Text: Concatenate, CharacterLengthOf, LengthOf, Pad, Replace, ToLower, ToText, ToUpper, Translate, Trim, Hash
- Date: DateAdd, DateDiff, DateLastDay, DatePart, IsValidDate
- Format: ASCII, EBCDIC, Unicode
Load
Load the results into one or more target systems such as a data lake, data warehouse, datamart, or business intelligence reporting system.
The data was extracted and transformed in the first two stages, now the resulting dataset must be loaded into a target system. This means your ETL software should be capable of connecting and loading data into a variety of targets.
Connectors: Flat files, XML, Oracle, IBM DB2, SQL Server, Teradata, Sybase, Vertica, Netezza, Greenplum, ODBC, JDBC, Hadoop Distributed File System (HDFS), Hive/HCatalog, Kafka, Mainframe (IBM z/OS), Salesforce.com, Tableau, QlikView
The ETL Value Equation

A complete end-to-end ETL process may take a few seconds or many hours to complete depending on the amount of data and the capabilities of the hardware and software.
The cost-time-value equation for ETL is defined by three characteristics:
- Volume – How much data needs to be processed? It may be hundreds of megabytes, terabytes, or even petabytes of data
- Velocity – How fast and how frequently does the data need to be processed? Is there a service level agreement (SLA) that needs to be met?
- Variety – What is the layout or format of the source data? How many different data sources need to be processed and combined? What is the format of the final output?
The selection of appropriate software, hardware and developer resources to meet these criteria will directly affect the overall cost and timeline of your ETL project.
Learn more – click on the image below:


Leave a comment