

It’s certainly not a new refrain, but in recent years IT managers are increasingly being told to do more with less – even as the number of new projects and requirements increase. Data is the fuel that powers most new business initiatives, but each project needs a slightly different blend of data sources and data formats. Clearly, data integration and ETL development can be a bottleneck that takes up a big chunk of overall project timelines. One of the main problems is that each new technology or target platform needs a whole new skillset or further training to get up to speed.
Consider just a selection of the language and API knowledge needed by the modern enterprise developer:
- Data Warehouse – SQL, shell script, Java, C/C++
- Mainframe – Cobol, JCL
- Big Data – Java, Scala, Python, HiveQL
- NoSQL and Cloud – REST APIs and web services
In-house development resources can be scarce and/or expensive, and outsourcing has its own set of management challenges. The idea of the data lake as a central repository where business users can perform their own manipulation of the data and bypass IT is a great idea, but it still needs some fairly rigorous IT underpinnings for a chance to be successful.
However, there’s another alternative to free up your developers from repetitive day-to-day grunt work so they can focus on more complex high-value projects.
Consider what the following capabilities could do for your organisation:
- Simple – a single graphical environment for all ETL work, with no coding or scripting required (Note 1)
- Platform Independent – an intelligent execution engine that runs on any platform – Linux, Unix, Windows, Hadoop, Spark, AWS, Google Cloud, Microsoft Azure – no recompiling needed
- Connected – source data from almost any business system: RDBMS, NoSQL, Mainframe, Cloud, streaming, flat files and more
Imagine a solution that grows and adapts easily to changing business requirements and management direction over time. Build the logic for a data transformation job once and deploy to a single onsite Windows server today, redeploy the same job to AWS or Google Cloud in six months’ time, then move the same job to Hadoop or Apache Spark the following year for the company’s new data hub initiative.
Precisely Connect is the modern data integration software your business needs to improve developer productivity and reduce ongoing maintenance overheads:
- Reduce the cost of re-platforming – build it once and run it on any target platform now and in the future
- Reduce time spent on performance tuning – with automatic performance optimisation for all target execution platforms
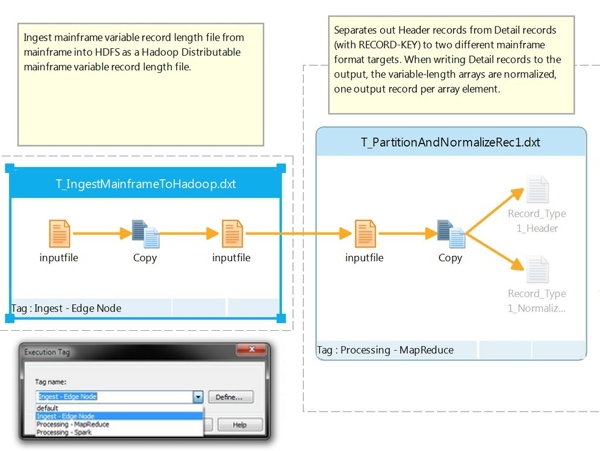
- Choose easy load-balancing – execute individual steps of your job flow on the most appropriate execution framework as required (see Figure 1)
Simplify development, reduce costs, and increase developer productivity with Precisely Connect.
Note 1: We know some users prefer coding and scripting solutions, so if you’re not a big fan of GUI development environments we’ve got you covered. Precisely Connect includes Data Transformation Language (DTL) for text-based coding of ETL jobs, while still providing all the performance and multi-platform benefits of jobs developed in the GUI. Plus, less technical colleagues can easily import DTL scripted jobs into the graphical interface as needed.

Leave a comment